








































































































































强连通分量与 Tarjan 缩点
连通分量与缩点
在说 四川菜),是原图的极大连通分量。这里的“极大”是一个文艺复兴时期提出的概念——若一个事物,没有比它更大的事物存在,就称这个事物是极大的/最大的(例如:导数的极大值)。
缩点,指在求出图上所有 大哥)。它可以做拓扑排序,在这样的图上做最短路,时间复杂度是
求解 整个世界就是一个巨大的 ),在图上做一遍深度优先搜索,并维护相关信息;以及不那么常用但是非常直观好理解的

假如当前
- 树枝边:正常的树内边,标记为黑色有向。
- 前向边:指向前方的边,也就是从上向下指的边。可以发现树枝边就是一类特殊的前向边。标记为蓝色有向
- 后向边:指向后方的边,与前向边相对。标记为橙色有向。
- 横叉边:指向一个已经访问过的节点,且这个节点不是它的父节点。标记为紫色有向。
如果某个节点是某个
算法思路
首先为每个节点维护两个变量 dfn 和 low,这两者都是维护节点信息的“时间戳”。前者用来记录深搜时该点是第几个被访问到的;后者定义为这个点在栈中能够回溯到的最早加入的节点 dfn。对于某个强连通分量,我们会发现这个分量中的所有点的 low 值均是相同的,如下图:
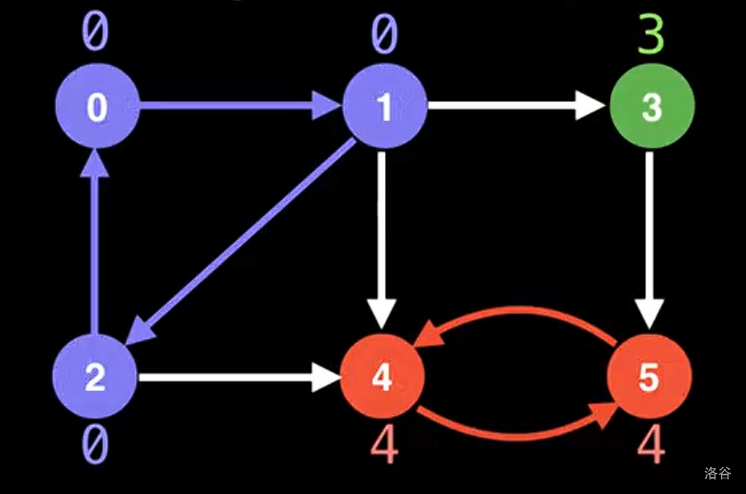
其中点内的序号是 dfn 值,点外侧的数字是 low 值。此时再维护一个栈,栈中存放已经深搜遍历到且还没计算出归属于哪个强连通分量的节点。
这启发我们做深搜,先把当前点 dfn 值标记出来,并枚举相连的点 low 值,分三种情况讨论:
- 如果枚举到一条树枝边,则
low[x] = min(low[x], low[y])。这基于一个事实——能到达的节点, 也能。 - 如果这条边不是树枝边,但是
在栈中,则 low[x] = min(low[x], dfn[y])。根据low的定义而来(有向图中使用low[x] = min(low[x], low[y])也是正确的)。 - 如果这条边不是树枝边,且
不在栈中,则不作操作。因为这意味着 所属的 已被全部处理完且弹出栈了,二者因此不同属于一个强连通分量中。
如果当前的点满足 dfn[u] = low[u],等价于它能回溯到的最早的点是自己,代表这是一个
基本模板:
void tarjan(int u) { stack<int> stk; dfn[u] = low[u] = ++dfs_cnt; stk.push(u); in_stk[u] = true;
for (int i = h[u]; ~i; i = edges[i].ne) { int j = edges[i].to; if (!dfn[j]) { tarjan(j); low[u] = min(low[u], low[j]); } else if (in_stk[j]) { low[u] = min(low[u], dfn[j]); } } if (dfn[u] == low[u]) { scc_cnt++; do { int t = stk.top(); stk.pop(); scc_id[t] = scc_cnt; } while (stk.top() != u); }}缩点流程
所谓缩点,说白了就是把解出来的强连通分量当作一个单点,建出一个新图,此时这个新图是一个
for (int i = 0; i <= n; i++) { for (int j = h[i]; ~j; j = edges[j].ne) { int k = edges[j].to; int a = scc_id[i], b = scc_id[k]; if (a != b) add(hs, a, b, edges[j].w); }}典例演练
为了方便,我们把缩点后入度为
洛谷 P2341 [USACO03FALL/HAOI2006] 受欢迎的牛 G
题目地址:P2341
题目难度:普及+/提高
每头奶牛都梦想成为牛棚里的明星。被所有奶牛喜欢的奶牛就是一头明星奶牛。所有奶牛都是自恋狂,每头奶牛总是喜欢自己的。奶牛之间的“喜欢”是可以传递的——如果
喜欢 , 喜欢 ,那么 也喜欢 。牛栏里共有 头奶牛,给定一些奶牛之间的爱慕关系,请你算出有多少头奶牛可以当明星。 输入格式:
第一行:两个用空格分开的整数:
和 。 接下来
行:每行两个用空格分开的整数: 和 ,表示 喜欢 。 输出格式:
一行单独一个整数,表示明星奶牛的数量。
数据范围:
对于
的数据, , 。
把所有的“喜欢关系”画成一个有向图:

强连通分量用绿色矩形框出,把绿色框当作一个点。已知框内的点两两互通,只要某个框内的某个点和另一个点连通,那么整个框的点都和这个点相通。因此连通关系就可以传递下来,于是我们需要解决的就是其他方框之间的连通性。
把绿色框看成单点(缩点)后,如果所有边最终汇聚到一个点上,那么这个 ヒマリ”。因此我们只需统计出度为
洛谷 P2746 [USACO5.3] 校园网 Network of Schools
题目地址:P2746
题目难度:提高+/省选-
一些学校连入一个电脑网络。那些学校已订立了协议:每个学校都会给其它的一些学校分发软件(称作“接受学校”)。注意即使
在 学校的分发列表中, 也不一定在 学校的列表中。 你要写一个程序计算,根据协议,为了让网络中所有的学校都用上新软件,必须接受新软件副本的最少学校数目(子任务 A)。更进一步,我们想要确定通过给任意一个学校发送新软件,这个软件就会分发到网络中的所有学校。为了完成这个任务,我们可能必须扩展接收学校列表,使其加入新成员。计算最少需要增加几个扩展,使得不论我们给哪个学校发送新软件,它都会到达其余所有的学校(子任务 B)。一个扩展就是在一个学校的接收学校列表中引入一个新成员。
输入格式:
输入文件的第一行包括一个正整数
,表示网络中的学校数目。学校用前 个正整数标识。 接下来
行中每行都表示一个接收学校列表(分发列表),第 行包括学校 的接收学校的标识符。每个列表用 结束,空列表只用一个 表示。 输出格式:
你的程序应该在输出文件中输出两行。
第一行应该包括一个正整数,表示子任务 A 的解。
第二行应该包括一个非负整数,表示子任务 B 的解。
数据范围:
。
我们同样处理出点之间的关系,图中一定有
对于子任务
洛谷 P2272 [ZJOI2007] 最大半连通子图
题目地址:P2272
题目难度:提高+/省选-
题目来源:浙江 2007 各省省选
一个有向图
称为半连通的 (Semi-Connected),如果满足: ,满足 或 ,即对于图中任意两点 ,存在一条 到 的有向路径或者从 到 的有向路径。 若
满足 , 是 中所有跟 有关的边,则称 是 的一个导出子图。若 是 的导出子图,且 半连通,则称 为 的半连通子图。若 是 所有半连通子图中包含节点数最多的,则称 是 的最大半连通子图。 给定一个有向图
,请求出 的最大半连通子图拥有的节点数 ,以及不同的最大半连通子图的数目 。由于 可能比较大,仅要求输出 对 的余数。 输入格式:
第一行包含两个整数
。 分别表示图 的点数与边数, 的意义如上文所述。 接下来
行,每行两个正整数 ,表示一条有向边 。图中的每个点将编号为 ,保证输入中同一个 不会出现两次。 输出格式:
应包含两行,第一行包含一个整数
,第二行包含整数 。 数据范围:
对于
的数据, , , 。
阅读题面可以发现,其实
对于方案数,考虑 DP。做最长链的时候,如果发现下一个状态能够被更新,则更新总点数、同时把上一个点的方案计数覆盖过去;如果转移时发现路径长度相等,则把上一个点的方案数累加过去。
这时,我们需要对缩点后的图去重边,因为在 DP 转移时需要枚举出边,重边会造成
AcWing 368 银河
题目地址:AcWing 368
题目难度:中等
银河中的恒星浩如烟海,但是我们只关注那些最亮的恒星。
我们用一个正整数来表示恒星的亮度,数值越大则恒星就越亮,恒星的亮度最暗是
。 现在对于
颗我们关注的恒星,有 对亮度之间的相对关系已经判明。 你的任务就是求出这
颗恒星的亮度值总和至少有多大。 输入格式:
第一行给出两个整数
和 。 之后
行,每行三个整数 ,表示一对恒星 之间的亮度关系。恒星的编号从 开始。 如果
,说明 和 亮度相等。 如果 ,说明 的亮度小于 的亮度。 如果 ,说明 的亮度不小于 的亮度。 如果 ,说明 的亮度大于 的亮度。 如果 ,说明 的亮度不大于 的亮度。 输出格式:
输出一个整数表示结果。
若无解,则输出
。 数据范围:
看到这道题,第一反应是差分约束,根据题干给出的大小关系建图,然后跑最长路并求和得到答案。但是这种方法基于 何况它已经死了),很容易超时。因此考虑用别的更优的算法解决。
联系到本文标题,使用
缩点后的图会变成一个
文章分享
如果这篇文章对你有帮助,欢迎分享给更多人!
评论区
音乐
暂未播放