








































































































































随机化高能骗分 模拟退火

退火与模拟退火
退火,是一种物理过程。指通过将固体加热到一定温度,并让温度缓慢降低,从而让高能的粒子能够在每个温度均达到平衡态,最终让整个固体变为内能最小的状态的过程。通常用这个方法来使固体硬度变得更高。
而模拟退火则是使用计算机语言模拟物理学中退火的过程,达到求多峰函数最优解近似值的功能。它通过设定一个模拟初始温度、以及一个终止温度(可以理解为精度)和一个衰减率,每次随机选取一个函数值,并随机邻域上的某个值,比较两值并优化答案,最终实现求近似解的功能。
一般来说,温度的衰减需要符合
世界上有很多无法在多项式时间内解决的问题(
下图展示了模拟退火找到全局最优解的过程:
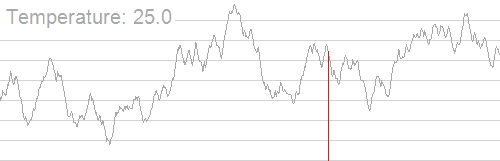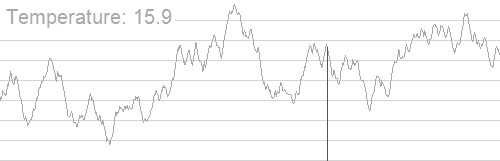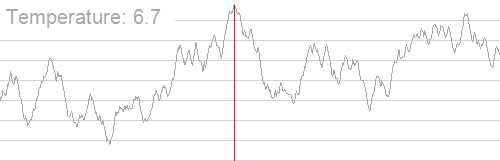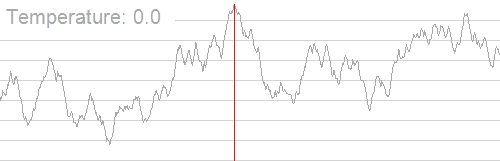
模拟退火核心函数如下:
void SA() { double T = 1e4; // 初始温度 while (T > 1e-4) { double d = calc(now) - calc(cur); // 计算差距 if (exp(-d / T) > rand(0, 1)) cur = now; // Metropolis 准则 T *= 0.99; // 按既定比率降温 }}更好的随机化选择
在平衡树的“如何生成更好的随机数”一节中,我们介绍了常用的三种随机数生成器 rand、random_device 和 mt_19937。接下来介绍一种听起来就非常牛逼的随机分布生成器 uniform_real_distribution。
整/实数均匀分布类
整数和浮点数版本分别对应 std::uniform_int_distribution 和 std::uniform_real_distribution。定义和普通的 STL 容器类似,需要指定存储类型,支持上下界约束。它在生成随机数时需要一个随机数生成引擎 std::default_random_engine 作为参数传入,理解为设置种子即可。
default_random_engine random(time(nullptr));uniform_int_distribution<int> dis1(0, 100);uniform_real_distribution<double> dis2(0.0, 1.0);
for(int i = 0; i < 10; ++i) cout << dis1(random) << ' ';cout << endl;
for(int i = 0; i < 10; ++i) cout << dis2(random) << ' ';cout << endl;输出:
70 5 91 57 87 15 52 72 62 960.806944 0.389546 0.951 475 0.530597 0.125625 0.622024 0.109438 0.735015 0.717254 0.954637生成带上下界的随机数
一般来说,对于
如果要生成
首先我们的
常见随机数生成模板
// 一般的随机数srand(time(nullptr));int x1 = rand();
// random devicerandom_device rd;unsigned x2 = rd();
// mt19937mt19937 mt(time(nullptr));unsigned x3 = mt();
// 均匀分布default_random_engine seed(time(nullptr));uniform_real_distribution<double> urd(L, R);uniform_int_distribution<int> uid(L, R);double x4 = urd(seed);int x5 = uid(seed);典例解析
POJ 3420/AcWing 3167/UVA 星星还是树
题目地址:AcWing 3167
题目难度:中等
在二维平面上有
个点,第 个点的坐标为 。 请你找出一个点,使得该点到这
个点的距离之和最小。 该点可以选择在平面中的任意位置,甚至与这
个点的位置重合。 输入格式:
第一行包含一个整数
。 接下来
行,每行包含两个整数 ,表示其中一个点的位置坐标。 输出格式:
输出最小距离和,答案四舍五入取整。
数据范围:
这是一道求解二维平面费马点的问题,可以使用模拟退火求解。首先拟定一个平面上的随机点,然后在它的周围区域随机一个新点,若更优则直接跳转到新点,否则则有一定几率跳到新点,整个过程遵循
#include <bits/stdc++.h>#define N 200using namespace std;
typedef pair<double, double> PDD;
PDD p[N];int n;double ans = 0x3f3f3f3f;
double dis(PDD i, PDD j) { return sqrt((i.first - j.first) * (i.first - j.first) + (i.second - j.second) * (i.second - j.second));}
double rand(double x, double y) { return (double) rand() / RAND_MAX * (y - x) + x;}
double calc(PDD x) { double sum = 0; for (int i = 1; i <= n; i++) sum += dis(p[i], x); ans = min(ans, sum); return sum;}
void SA() { double T = 1e4; PDD cur = (PDD) {rand(0, 1e4), rand(0, 1e4)}; while (T > 1e-4) { PDD now = (PDD) {rand(cur.first - T, cur.first + T), rand(cur.second - T, cur.second + T)}; double d = calc(now) - calc(cur); if (exp(-d / T) > rand(0, 1)) cur = now; T *= 0.99; }}
int main() { ios::sync_with_stdio(false); cin.tie(nullptr); cout.tie(nullptr);
srand(time(nullptr)); cin >> n; for (int i = 1; i<= n; i++) cin >> p[i].first >> p[i].second; double st = clock(); while (clock() - st <= 985) SA(); cout << (int) round(ans) << endl; return 0;}洛谷 P4044 [AHOI2014/JSOI2014] 保龄球
题目地址:P4044
题目难度:省选/NOI-
题目来源:安徽 江苏 2014
JYY 很喜欢打保龄球,虽然技术不高,但是还是总想着的高分。这里 JYY 将向你介绍他所参加的特殊保龄球比赛的规则,然后请你帮他得到尽量多的分数。
一场保龄球比赛一共有
个轮次,每一轮都会有十个木瓶放置在木板道的另一端。每一轮中,选手都有两次投球的机会来尝试击倒全部的十个木瓶。对于每一次投球机会,选手投球的得分等于这一次投球所击倒的木瓶数量。选手每一轮的得分是他两次机会击倒全部木瓶的数量。 对于每一个轮次,有如下三种情况:
1、 “全中”:如果选手第一次尝试就击倒了全部十个木瓶,那么这一轮就为“全中”。在一个“全中”轮中,由于所有木瓶在第一次尝试中都已经被击倒,所以选手不需要再进行第二次投球尝试。同时,在计算总分时,选手在下一轮的得分将会被乘2计入总分。
2、“补中”:如果选手使用两次尝试击倒了十个木瓶,那么这一轮就称为“补中”。同时,在计算总分时,选手在下一轮中的第一次尝试的得分将会以双倍计入总分。
3、“失误”:如果选手未能通过两次尝试击倒全部的木瓶,那么这一轮就被称为“失误”。同时,在计算总分时,选手在下一轮的得分会被计入总分,没有分数被翻倍。此外,如果第
轮是“全中”,那么选手可以进行一次附加轮:也就是,如果第 轮是“全中”,那么选手将一共进行 轮比赛。显然,在这种情况下,第 轮的分数一定会被加倍。 附加轮的规则只执行一次。也就是说,即使第
轮选手又打出了“全中”,也不会进行第 轮比赛。因而,附加轮的成绩不会使得其他轮的分数翻番。最后,选手的总得分就是附加轮规则执行过,并且分数按上述规则加倍后的每一轮分数之和。 JYY 刚刚进行了一场
个轮次的保龄球比赛,但是,JYY非常不满意他的得分。JYY想出了一个办法:他可以把记分表上,他所打出的所有轮次的顺序重新排列,这样重新排列之后,由于翻倍规则的存在,JYY就可以得到更高的分数了! 当然了,JYY不希望做的太假,他希望保证重新排列之后,所需要进行的轮数和重排前所进行的轮数是一致的:比如如果重排前JYY在第
轮打出了“全中”,那么重排之后,第 轮还得是“全中”以保证比赛一共进行 轮;同样的,如果 JYY 第 轮没有打出“全中”,那么重排过后第 轮也不能是全中。请你帮助 JYY 计算一下,他可以得到的最高的分数。 输入格式:
第一行包含一个整数
,表示保龄球比赛所需要进行的轮数。 接下来包含
或 行,第i行包含两个非负整数 ,表示 JYY 在这一轮两次投球尝试所得到的分数, 表示第一次尝试, 表示第二次尝试。 特别地,
10 0表示一轮“全中”。读入数据存在
行,当且仅当 且 。 输出格式:
输出一行一个整数,表示 JYY 最大可能得到的分数。
数据范围:
对于
的数据, 。
首先考虑随机一个排列并计算出当前排列的得分,在邻域上随机可以看作将该序列随机交换元素。有了这个思路,直接跑模拟退火即可。
#include <bits/stdc++.h>#define N 55using namespace std;
typedef pair<int, int> PII;
random_device rd;
PII p[N];int n, m;int ans;
int calc() { int sum = 0; for (int i = 1; i <= m; i++) { sum += (p[i].first + p[i].second); if (i <= n) { if (p[i].first == 10) sum += (p[i + 1].first + p[i + 1].second); else if (p[i].first + p[i].second == 10) sum += p[i + 1].first; } } ans = max(ans, sum); return sum;}
void SA() { double T = 1e4; while (T > 1e-5) { int a = calc(); unsigned x = rd() % m + 1, y = rd() % m + 1; swap(p[x], p[y]); if (n + (p[n].first == 10) == m) { int b = calc(); if (exp((b - a) / T) < (double) rd() / random_device::max()) swap(p[x], p[y]); } else swap(p[x], p[y]); T *= 0.99; }}
int main() { ios::sync_with_stdio(false); cin.tie(nullptr); cout.tie(nullptr);
cin >> n; double st = clock(); for (int i = 1; i <= n; i++) cin >> p[i].first >> p[i].second; if (p[n].first == 10) { m = n + 1; cin >> p[n + 1].first >> p[n + 1].second; } else m = n; while ((clock() - st) / CLOCKS_PER_SEC < 0.85) SA(); cout << ans << endl; return 0;}洛谷 P2503 [HAOI2006] 均分数据
题目地址:P2503
题目难度:提高+/省选-
题目来源:河南 2006
已知
个正整数 。今要将它们分成 组,使得各组数据的数值和最平均,即各组数字之和的均方差最小。均方差公式如下: 其中
为均方差, 为各组数据和的平均值, 为第 组数据的数值和。 输入格式:
第一行是两个整数,表示
的值( 是整数个数, 是要分成的组数) 第二行有
个整数,表示 。整数的范围是 。 (同一行的整数间用空格分开)
输出格式:
输出一行一个实数,表示最小均方差的值(保留小数点后两位数字)。
数据范围:
对于
的数据,保证有 ,
这道题如果还像上一道题一样随机排列然后交换两数并枚举分组情况,显然是很低效的。考虑这样一个基于贪心的优化方法——让每组的平均数尽量相近。这样一来就可以避免无意义的枚举了,剩下的就和上一道题是一样的了。
#include <bits/stdc++.h>
#define N 25#define M 10using namespace std;
int seq[N], grp[M];double ans = 1e9;random_device rd;int n, m;
double rand(double l, double r) { return (double) rd() / random_device::max() * (r - l) + l;}
double calc() { memset(grp, 0, sizeof grp);
double ret = 0; for (int i = 1; i <= n; i++) { int t = 1; for (int j = 1; j <= m; j++) { if (grp[j] < grp[t]) t = j; } grp[t] += seq[i]; } double avr = 0; for (int i = 1; i <= m; i++) avr += (double) grp[i] / m; for (int i = 1; i <= m; i++) ret += (grp[i] - avr) * (grp[i] - avr); ret = sqrt(ret / m); ans = min(ans, ret); return ret;}
void SA() { shuffle(seq + 1, seq + 1 + n, mt19937(rd())); double T = 1e6; while (T > 1e-6) { double a = calc(); int x = (int) rand(1, n), y = (int) rand(1, n); swap(seq[x], seq[y]); double b = calc(); if (exp((a - b) / T) < rand(0, 1)) swap(seq[x], seq[y]); T *= 0.99; }}
int main() { ios::sync_with_stdio(false); cin.tie(nullptr); cout.tie(nullptr);
cin >> n >> m; for (int i = 1; i <= n; i++) cin >> seq[i]; double st = clock(); while ((clock() - st) / CLOCKS_PER_SEC < 0.85) SA(); cout << fixed << setprecision(2) << ans << endl; return 0;}文章分享
如果这篇文章对你有帮助,欢迎分享给更多人!
评论区
音乐
暂未播放